
本文是我设计「金融 AI 科研助手平台(FinSci AI)」的完整工程复盘。不是教程,而是对核心架构决策、踩坑经验和量化评测结果的系统性整理,希望对同样在探索大模型落地的同学有所参考。量化评测部分使用了中国人民大学官方发布的金融 RAG 评测基准 OmniEval(含 HAL/UTL/REL 等维度)。
一、为什么要做这个系统
在金融投研场景中,通用大语言模型有一个致命缺陷:事实性幻觉。
让模型直接回答「某公司 2023 年的营收增速是多少」,它大概率会给你一个措辞流畅但数字完全错误的回答。金融业务要求的是可审计的计算器,而不是发散的文案机。
RAG(检索增强生成)是当前业内应对这一问题的主流方案,但绝大多数项目停留在「把检索到的文本塞进 Prompt」这一层面,本质上仍然是个黑盒:你不知道模型用了哪些内容、忽略了哪些内容,也无法追责。
FinSci AI 的核心目标是:证据驱动生成、全流程可追溯。每一句有数据支撑的回答,都必须能溯源到具体的文档片段;知识库无法覆盖的问题,系统要主动闭嘴而不是胡说。
二、系统总体架构
整个系统前后端分离,构建了标准的四层全栈架构。
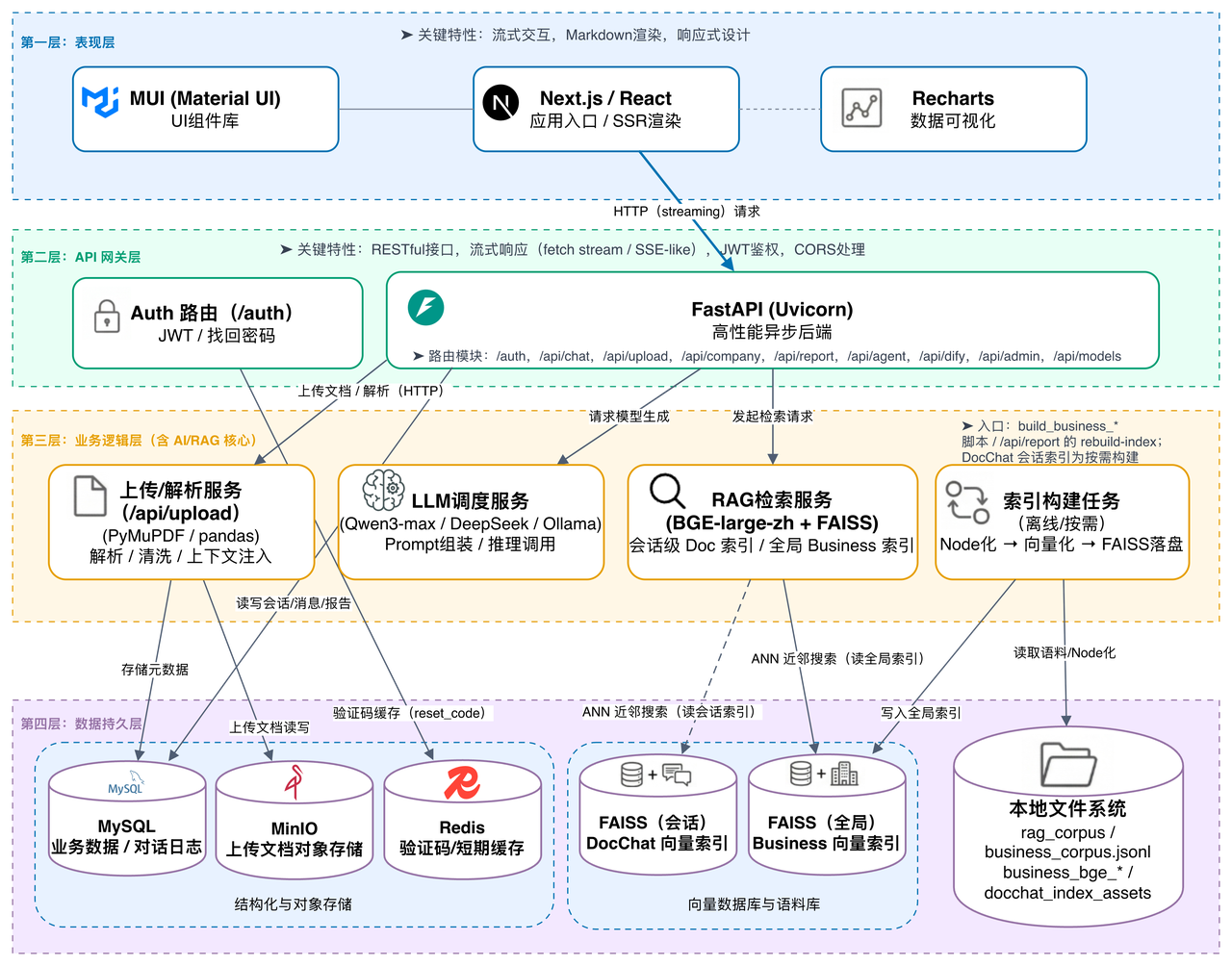
前端通过 SSE(Server-Sent Events)接收后端逐块推送的 LLM token,实现实时增量渲染。
这是本系统在高并发对话场景下保障低延迟的核心机制,后文会详细展开。
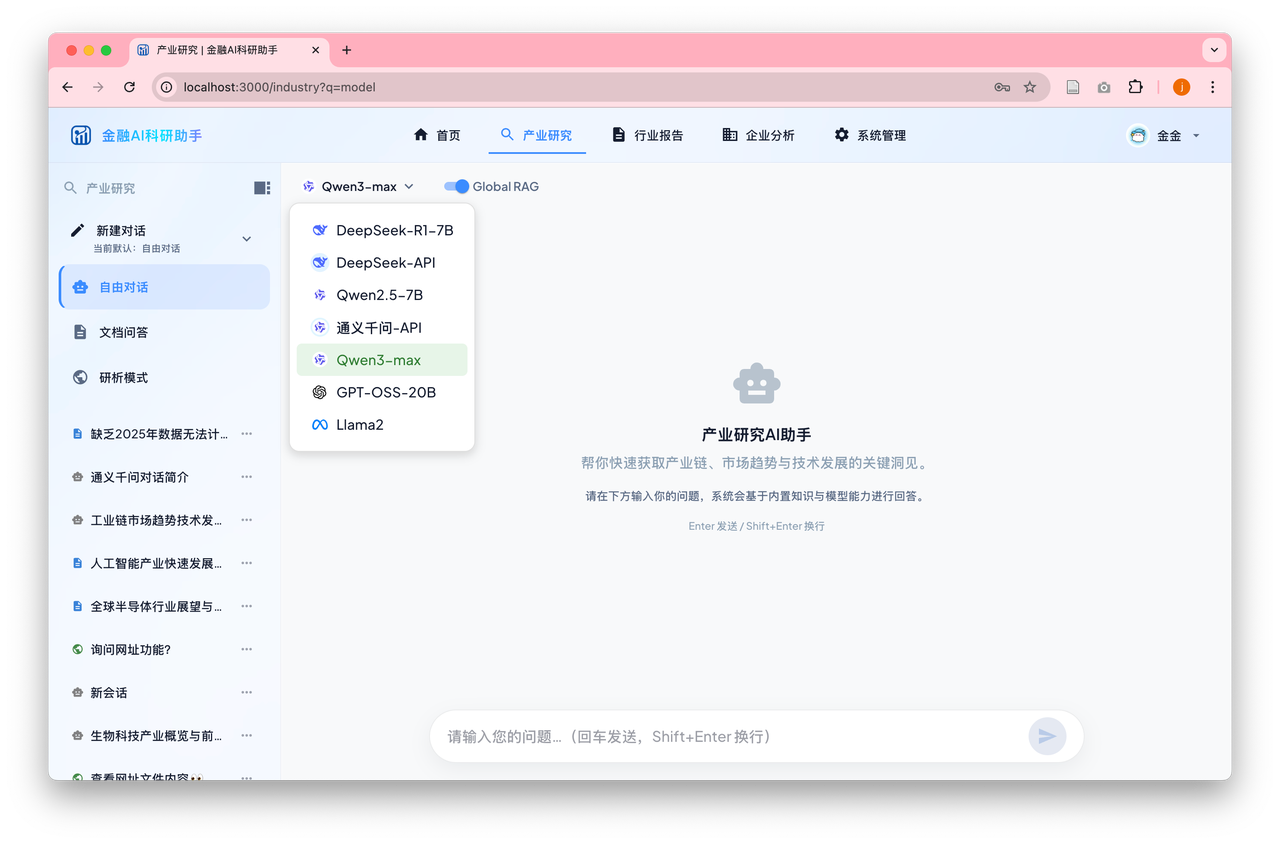
系统支持三种对话模式:
自由对话(free_chat):纯 LLM 问答,可选接入全局知识库(Global RAG)
文档问答(doc_chat):用户上传私有研报/财报,在会话沙箱内检索作答
研析模式(web_chat):输入网页 URL,通过 Dify Agent 对在线内容进行问答
三、核心亮点一:差异化切块 + 双轨检索隔离
3.1 为什么不能用固定长度硬切分
金融语料里混合了两种截然不同的内容:
非结构化长文:宏观研报、行业分析,上下文语义高度连续
结构化表格:财报指标,每一行都是独立的数字事实
对这两类内容用同一种切法,必然出问题:
固定硬切会在表格中间截断一行,导致「某公司 2023 年营收(换块)139 亿元」变成两个残缺片段,检索时两个都命不中
1000 字的滑窗会把一个三行的指标表格变成 3 条语义相似度极高的冗余片段,Top-K 全被它们占据
3.2 差异化切块策略
对非结构化长文:采用滑窗切块,1200 字符窗口 + 150 字符重叠,保留边界上下文。
1 |
|
对结构化表格:在构建业务知识库(business_corpus.jsonl)的阶段,
将每一行预处理为 "列名=值" 格式的自描述短文本节点,按行入库,
检索时直接命中具体的数字行,彻底避免跨行截断。
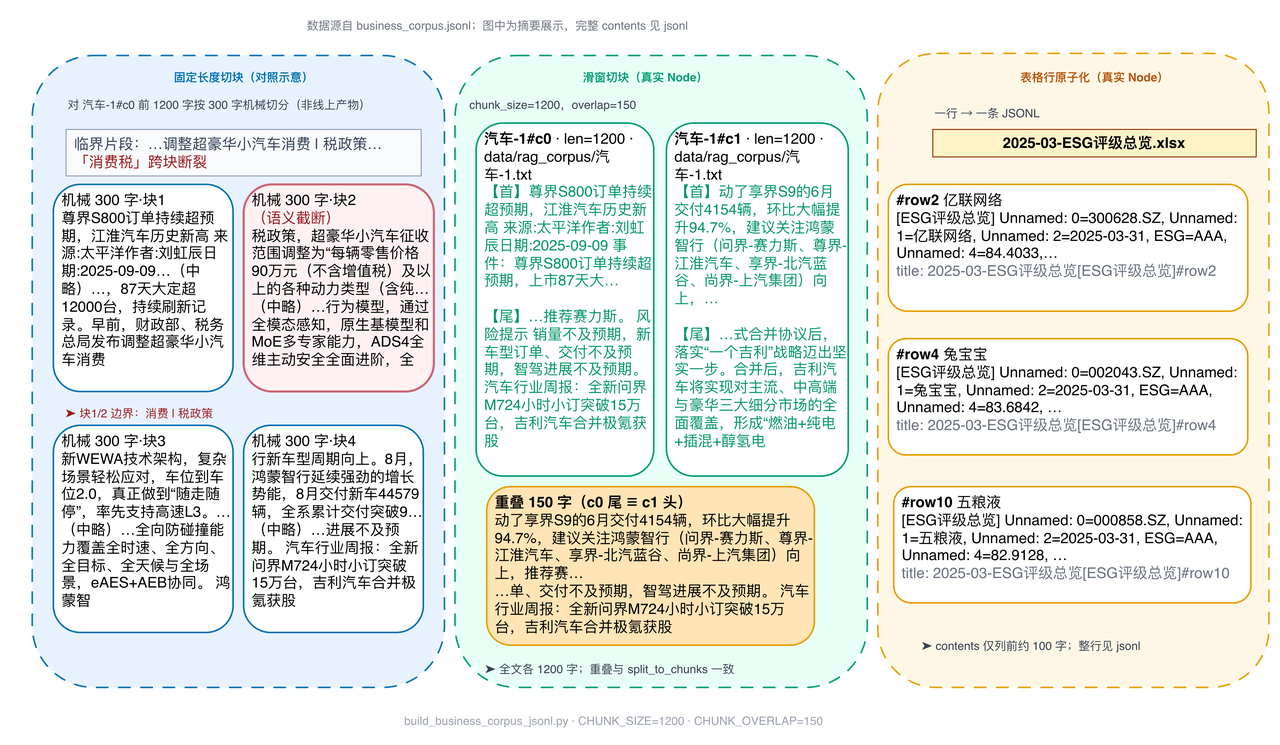
3.3 双轨检索隔离
系统在底层维护两套完全独立的 FAISS 索引,服务于不同的隐私与合规边界:
全局业务知识库(business_bge_1200):
预置超 33 万个向量节点,服务于宏观行业调研与自由对话的 Global RAG 模式
使用 BGE-large-zh-v1.5 编码,与 OmniEval 评测基准(中国人民大学官方发布) 对齐
会话级文档沙箱(doc_only):
用户每次上传研报时,系统按
session_id构建独立的 FAISS 内存索引执行
source_scope: 'doc_only'策略,搜索域严格限定在当前会话的文档集会话索引同时落盘到
index_store/docchat_session/{session_id}/,服务重启后可复用
1 |
|
两套索引的物理隔离确保:用户 A 上传的私有财报绝不会出现在用户 B 的检索结果中。
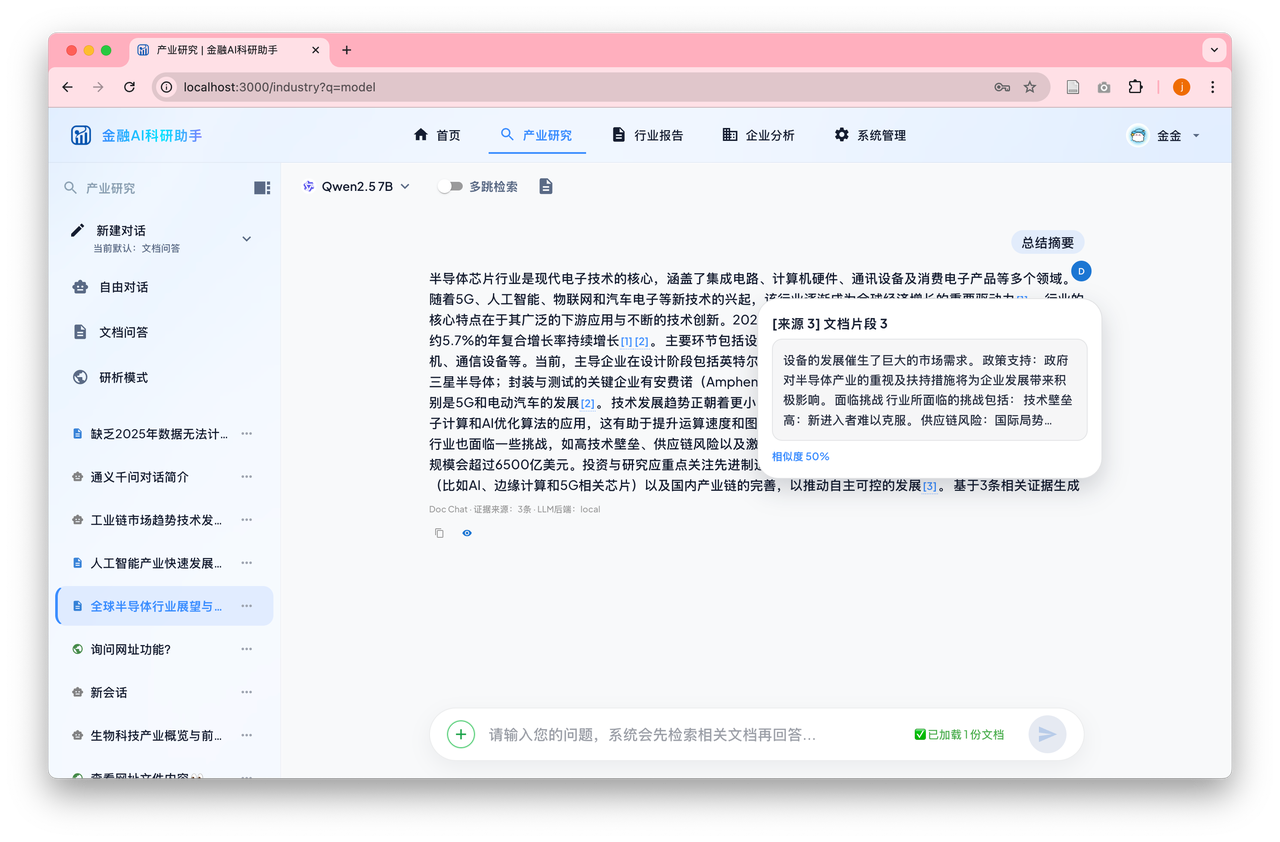
四、核心亮点二:端到端证据溯源与「无证据不生成」硬防线
这是我认为整个系统里最值得单独讲一讲的设计,也是区别于大多数 RAG Demo 的核心差异。
4.1 架构级硬拒答
在 FAISS 检索出 Top-K=8 片段后,系统对每个片段做余弦相似度(内积)下限过滤:
1 |
|
过滤后如果命中集为空,Prompt 中有明确的硬约束:
1 |
|
「宁可主动闭嘴,绝不胡编乱造」——这条原则在评测阶段被量化验证,后文会展示数据。
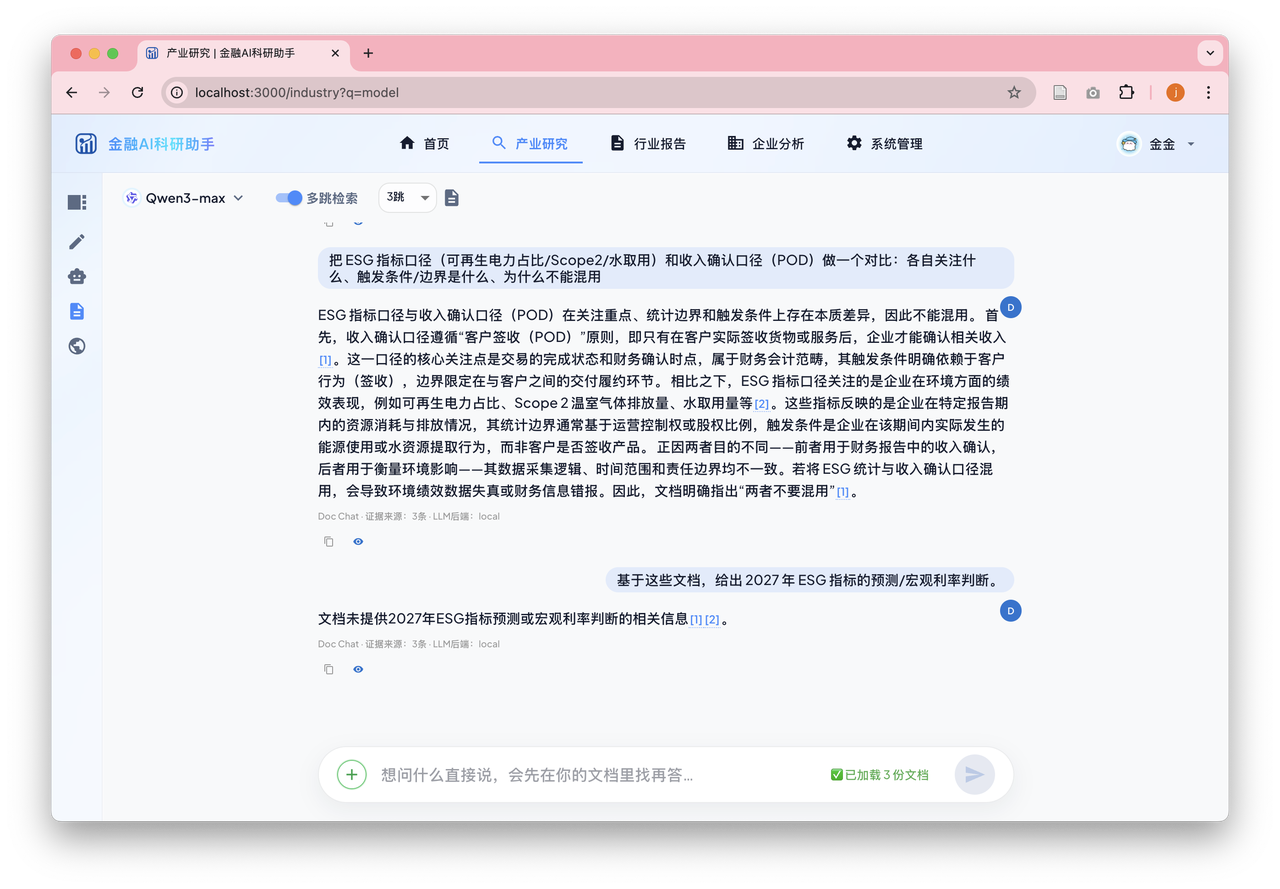
4.2 证据优先的 SSE 推流协议
一个常被忽视的工程细节:前端要渲染内联引用卡片,必须在 LLM 生成任何 token 之前就拿到证据数据。
我在 SSE 流的最开头先推一个 meta 事件,包含全部命中片段的 JSON,然后再开始推 LLM token:
1 |
|
前端收到 meta 事件后,建立引用编号到证据对象的映射表。LLM 回答文本里每出现 [1],
就从映射表里找到对应的片段,渲染成可交互的 EvidenceHoverCard 组件。
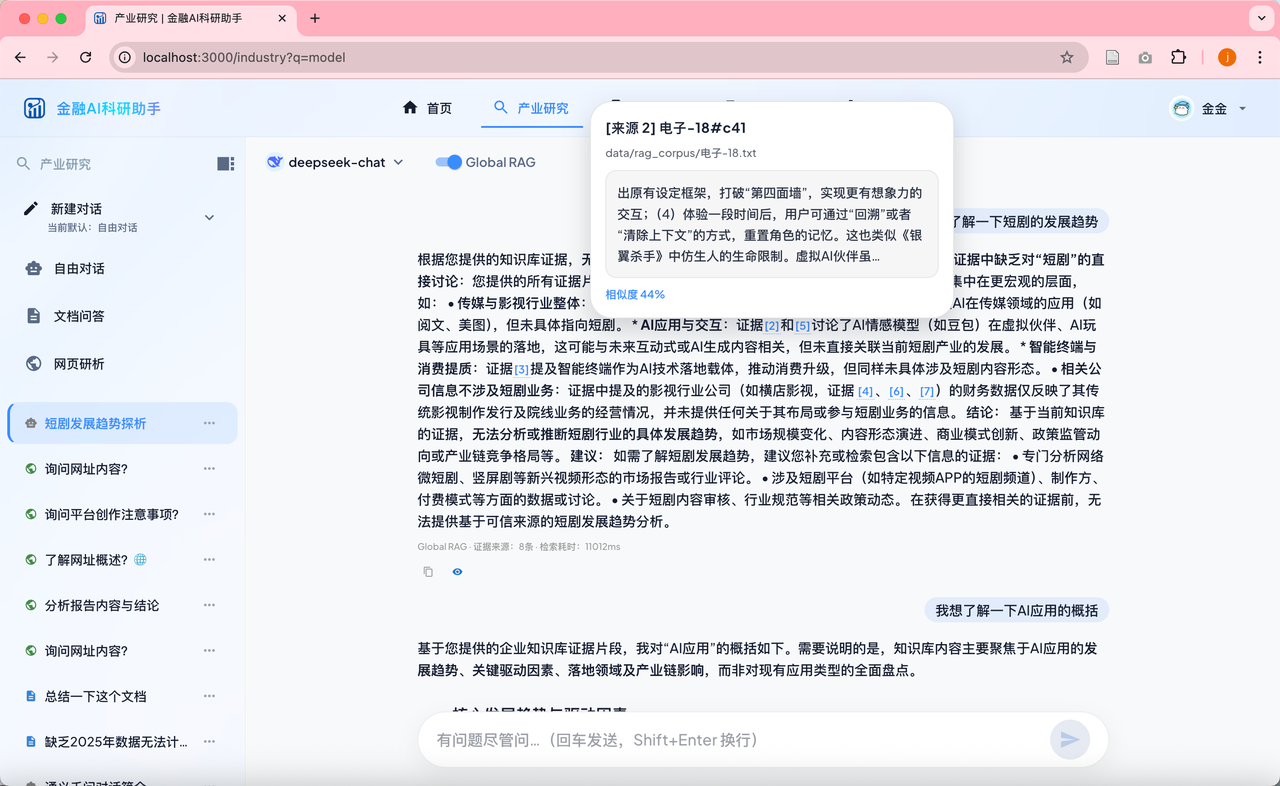
4.3 EvidenceHoverCard:从回答到原文,一次悬停
这是整个系统里用户感知最直接的设计。
1 |
|
4.4 证据的 100% 持久化
助手回复对应的证据,全量以 JSON 格式落到 chat_message 表的 evidence_source 字段:
1 |
|
evidence_source 字段存储的结构如下:
1 |
|
这意味着:任何一条问答记录,都可以在数据库里精确还原当时 LLM 参考了哪些内容——满足金融场景的审计要求。
五、核心亮点三:超越 CRUD 的 FinOps 平台治理
一个真正面向生产的 AI 系统,不能只有对话框。
每次 LLM 调用结束后,后端在 finally 块中异步记录用量数据:
1 |
|
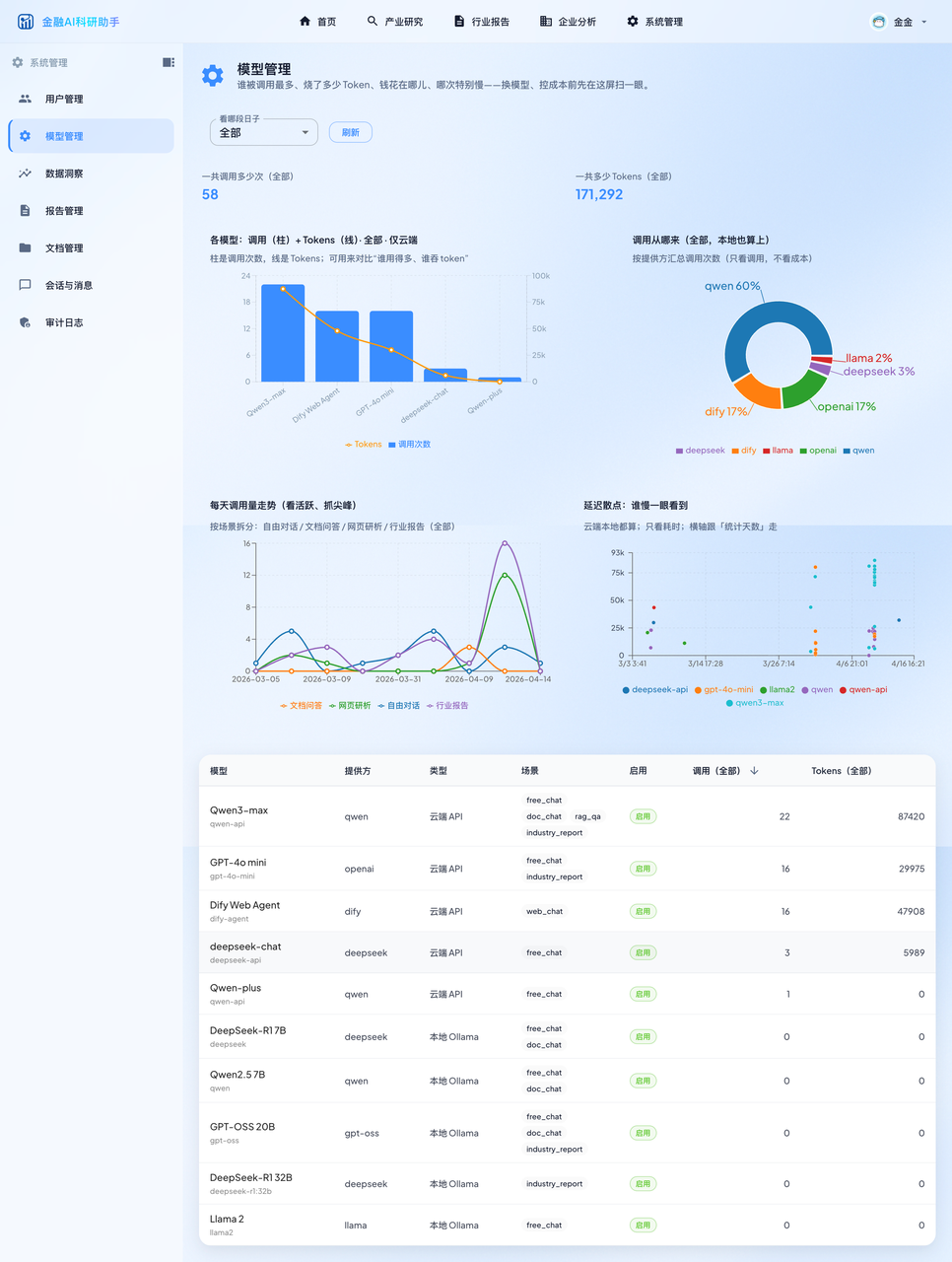
llm_usage_log 表记录每次调用的发起人、业务场景、Token 消耗、响应延迟与预估成本,
前端用 Recharts 构建了多维度的可视化大屏:
各模型调用频次 + Token 消耗双轴组合图
响应延迟分布散点图(发现性能波动点)
合规审计日志台账(追踪用户登录、文档删除操作)
六、行业报告生成
除对话功能外,系统还集成了面向行业研究的自动报告生成模块。
用户输入关键词(如「新能源储能」),后端从 33 万节点的业务知识库中检索相关语料,
通过分段式 Prompt 驱动 LLM 生成结构化的行业调研报告(含行业现状、竞争格局、风险提示等章节),
结果存入 report 表并支持前端查看历史报告。
七、量化评测:拒绝自嗨,用数据说话
7.1 评测基准
依托业内的 **OmniEval 金融 RAG 评测框架(中国人民大学官方发布)**,对系统进行双轨离线评测:
Rule-based:ROUGE、精确匹配等字面指标
LLM-as-a-Judge:由 GPT 系列模型对答案的幻觉率(HAL)、证据利用率(UTL)、相关性(REL)等维度进行语义打分
主测试集 n=594,受控变量实验(固定语料库,对比裸答 vs RAG 接入)。
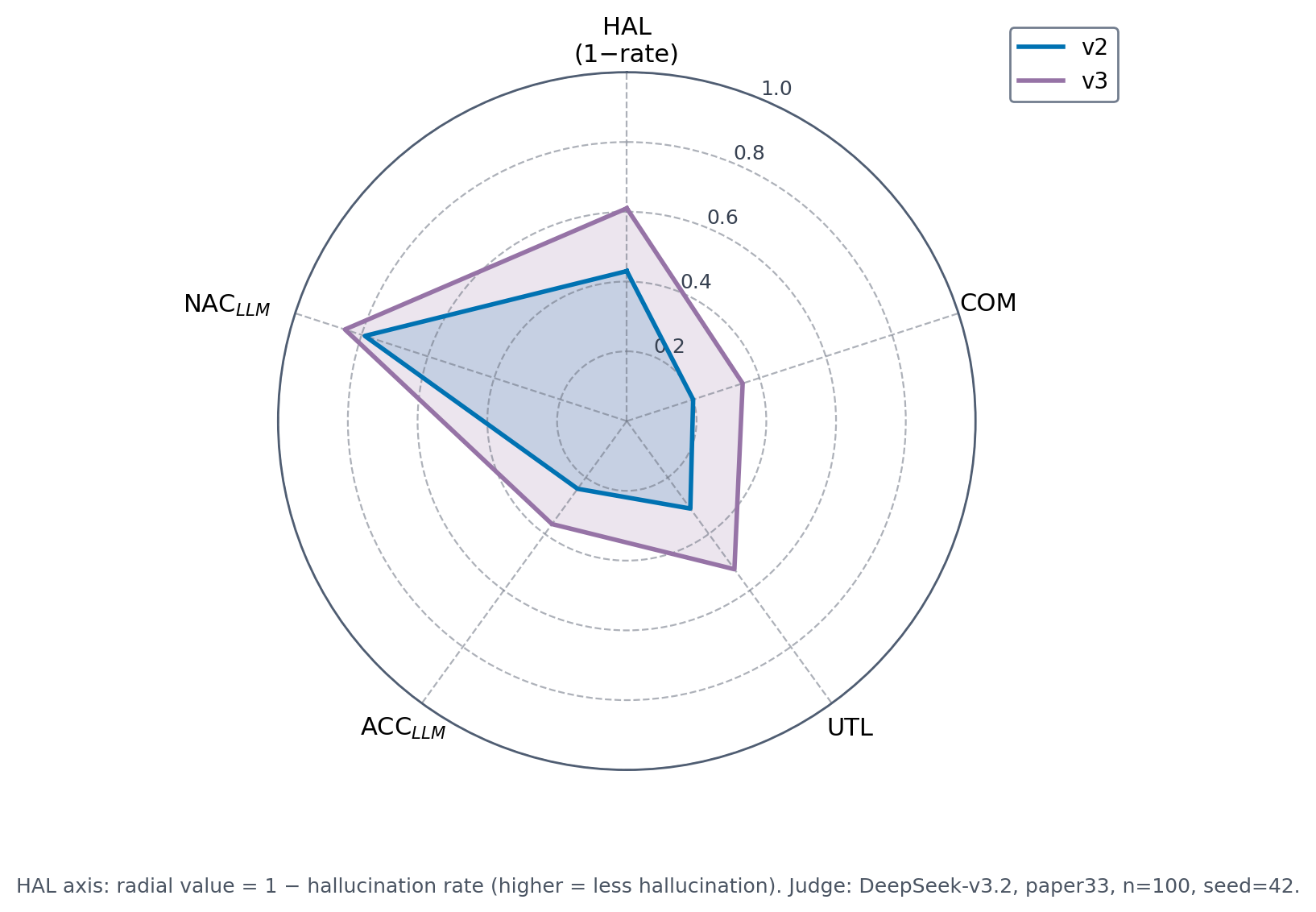
7.2 核心结果
| 维度 | 裸答(无 RAG) | RAG(BGE + Top-8 + Qwen3-max) |
||::|::|
| 幻觉率 HAL | 0.88 | 0.39 |
| 证据利用率 UTL | — | 显著提升 |
| 相关性 REL | — | 持平或提升 |
引入 RAG 后,语义幻觉率从 0.88 断崖式骤降至 0.39(HAL 评分越高代表幻觉越严重,满分为 1)。
人工盲审(n=100)三分法结果:
有效拒答:29%(知识库未覆盖的问题,系统主动拒答)
正确作答:64%
真实错误:仅 7%
这组数字证明了「合规拦截 + Prompt 约束」的组合确实生效了:面对刁钻问题,系统做到了「知之为知之,不知为不知」。
八、踩坑复盘
8.1 ROUGE 指标会骗你
评测初期,我用 ROUGE-L 来衡量答案质量,结果发现一个反直觉现象:
引入 RAG 后,模型给出的是「有完整证据支撑的详细分析」,ROUGE 得分反而比「裸答一个短词」还低。
原因很简单:ROUGE 算的是和参考答案的字面重叠,而参考答案往往很短。
一个 200 字的准确分析,与一个 5 字的参考答案的 ROUGE-L 远低于直接输出那 5 个字的裸答。
教训:在垂直 AI 应用的评测中,字面匹配指标只能作为辅助参考,核心指标必须是语义打分(LLM-as-a-Judge)和人工盲审,不能被 ROUGE 绑架。
8.2 多跳推理的瓶颈在首跳,不在生成端
DocRAG 支持多跳检索(multi-hop):先检索一次,再让模型生成 2-3 个子问题,对子问题分别检索,合并后作答。
实验中发现:无论生成端的 Prompt 怎么优化,如果首跳检索没有精确命中关键实体,后续所有子问题的检索都是在「噪声证据」上展开的,最终答案质量无法提升。
1 |
|
教训:优化多跳任务,首先要提升首跳的嵌入质量(更换更强的 embedding 模型、改善语料的节点粒度),而不是在 Prompt 上做文章。
8.3 SSE 推流与数据库写入的异步冲突
SSE 的 StreamingResponse 会持续占用一个 FastAPI 工作线程直到流结束。
如果在推流过程中频繁做同步的 db.commit(),极易出现以下问题:
数据库连接池满载(连接被长时间占用而不释放)
推流速度骤降(同步 I/O 阻塞在 async 上下文里)
高并发下出现 504 / 连接超时
最终的解法是将所有数据库写入(证据 JSON 落库、LLM 用量统计)统一放到 token_stream() 的 finally 块里,等流式生成完全结束后再做一次性批量落库:
1 |
|
这个改动彻底解决了高并发场景下的响应卡顿问题。
九、总结
FinSci AI 作为我的本科收官之作,覆盖了从全栈工程到 RAG 算法调优、再到系统合规安全的完整链路。
回看整个开发过程,最深的体感是:
RAG 不是「把文本塞进 Prompt」,而是一套需要精心设计的工程系统。
切块粒度、检索边界、证据过滤阈值、Prompt 约束的严格程度——每一个环节都会对最终的生成质量和合规性产生实质性影响。
量化评测(而不是主观感受)是验证这些决策是否有效的唯一可信方式。
—— 本文完 · 感谢读到这里的你 🐾 ——